
AI Summary
In AI search, 'Trust (EEAT)' is defined not merely by exposure, but by a structural pattern that repeatedly converges on specific sources. Analysis of 2.2 million data points shows that while some anchors exist, the choice of sources remains dispersed and not yet stabilized across the industry. Therefore, rather than the amount of content or brand exposure, the key criterion is whether the same source is consistently chosen.
One of the most frequently mentioned concepts in the AI search environment is EEAT, or "trust." Many people argue that "sources trusted by AI are important" and that "strengthening EEAT will benefit AI search." However, little research has been conducted on what "trust" actually is and whether it is actually a structurally observable phenomenon.
Therefore, ChainShift rephrased the question: How should "trust" in AI search be observed? To this end, we defined a citation source trusted by AI as follows:
A phenomenon in which sources repeatedly referenced by AI in the same query converge to a small number of identical nodes (anchors).
In other words, our hypothesis is that trust will be observed not as an abstract concept of reputation score or brand awareness, but as a structural pattern of repetition and convergence. If AI consistently selects a specific domain or source, it means that that node is functioning as an anchor in the retrieval layer. We viewed this as an observable form of "trust formation." This definition also served as an attempt to verify another claim. In the field of AI search optimization, it's often said that "continuous content publishing stabilizes the AI knowledge graph." However, this too has not been empirically verified. Does AI's evidence selection truly converge on a specific node when content is abundant? Or does it remain distributed? To confirm this, we analyzed approximately 2.2 million response data related to the electronics industry from September 2025 to January 2026. We intentionally avoided examining response sentences or mere impression counts. Instead, we observed the distribution of host_urls selected by AI within the same set of questions and measured the convergence of evidence selection using the following four indicators.
- RCR (Reference Concentration Ratio): Concentration in top sources
- Entropy: Dispersion of evidence selection
- Persistence: Percentage of repeated appearances of the same anchor
- BAS (Brand Anchor Share): Percentage of brand domains
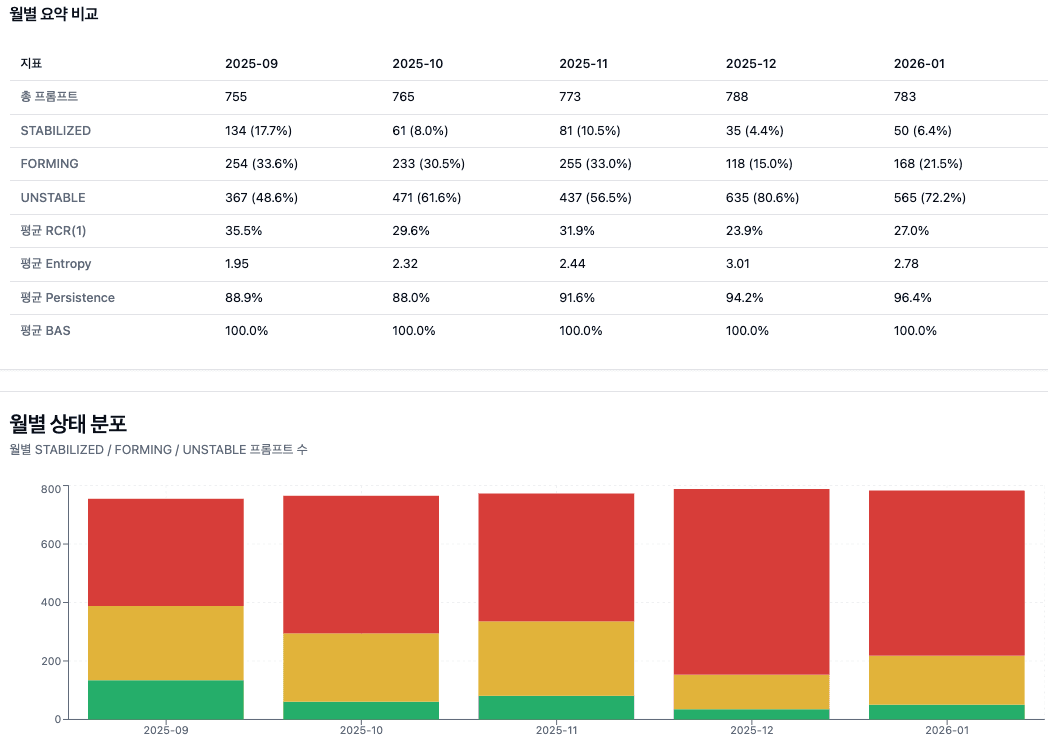
The results were relatively clear. While anchor formation was observed in some question groups, it was difficult to say that the retrieval layer was structurally stable at the industry level. The STABILIZED ratio actually showed a period of decline, while the average entropy increased. This suggests that the AI is still selecting diverse sources in a distributed manner, rather than gradually converging to a specific reference point. Interestingly, the persistence remained high, indicating that the AI is not acting completely randomly. There is a tendency to repeatedly refer to certain sources. However, this repetition did not lead to the formation of strong anchors. In other words, repetition did not automatically lead to convergence. The fact that the BAS remained at 100% also provides an important implication. The constant appearance of a brand domain is significant in terms of exposure. However, if the RCR is low and the entropy is high, the brand's "appearance" and its "reference" are completely different matters. Exposure and anchoring are not synonymous concepts.
Ultimately, this experiment attempted to answer two questions. First, can "trust" in AI search be defined as a structural pattern of convergence in repeated evidence selection? Second, does content publishing actually lead to the stabilization of the retrieval layer? The 2.2 million data points from the electronics industry demonstrate that, at least at present, the industry-wide retrieval layer is not yet structurally fixed. While anchors are formed in some areas, the selection of evidence remains fragmented across most query sets.
In other words, EEAT in AI search cannot be explained simply by the amount of content or brand exposure. Trust should be observed not as "frequent appearance," but as "repeatedly and identically selected." Only when this convergence is confirmed in real-world data can we say that the retrieval layer has stabilized.
Chainshift Daniel © 2026 ChainShift. All rights reserved. Unauthorized reproduction and redistribution prohibited.