
AI 요약
AI 검색에서의 ‘신뢰(EEAT)’는 단순 노출이 아니라, 특정 출처로 반복적으로 수렴되는 구조적 패턴으로 정의됩니다. 220만 건 데이터 분석 결과, 일부 anchor는 존재하지만 산업 전반은 여전히 출처 선택이 분산되어 안정화되지 않은 상태입니다. 따라서 콘텐츠 양이나 브랜드 노출보다, 동일한 출처가 지속적으로 선택되는지가 핵심 기준이 됩니다.
AI 검색 환경에서 가장 많이 언급되는 개념 중 하나는 EEAT, 즉 ‘신뢰도’입니다. 많은 사람들이 “AI가 신뢰하는 출처가 중요하다”, “EEAT를 강화하면 AI 검색에서 유리하다”고 말합니다. 그러나 정작 그 ‘신뢰’가 무엇인지, 그리고 그것이 실제로 구조적으로 관측 가능한 현상인지에 대한 검증은 거의 이루어지지 않았습니다.
그래서 체인시프트는 질문을 이렇게 바꿨습니다.
AI 검색에서 말하는 ‘신뢰’는 과연 어떤 현상으로 관측되어야 하는가?
이를 위해 우리는 AI가 신뢰하는 citation source를 다음과 같이 정의했습니다.
같은 질문군에서 AI가 반복적으로 참조하는 근거 출처가, 소수의 동일 노드(anchor)로 수렴하는 현상.
즉, 신뢰를 추상적인 평판 점수나 브랜드 인지도 개념이 아니라, 반복성과 수렴성이라는 구조적 패턴으로 관측하겠다는 가설입니다. 만약 AI가 특정 도메인이나 출처를 일관되게 선택한다면, 그것은 Retrieval Layer 상에서 해당 노드가 기준점(anchor)으로 기능하고 있음을 의미합니다. 우리는 이를 곧 ‘신뢰 형성’의 관측 가능한 형태로 보았습니다.
이 정의는 동시에 또 하나의 주장을 검증하기 위한 시도이기도 했습니다. AI 검색 최적화 영역에서는 “콘텐츠를 지속적으로 발행하면 AI 지식 그래프가 안정화된다”는 이야기가 자주 등장합니다. 하지만 이 역시 실증적으로 검증된 명제는 아니었습니다. 정말로 콘텐츠를 채우면 AI의 근거 선택이 특정 노드로 수렴하는가? 아니면 여전히 분산된 상태로 유지되는가?
이를 확인하기 위해 2025년 9월부터 2026년 1월까지, 전자 업계 관련 약 220만 건의 답변 데이터를 분석했습니다. 우리는 의도적으로 답변 문장이나 단순 노출 수를 보지 않았습니다. 대신 동일 질문군에서 AI가 선택한 host_url의 분포를 관찰하고, 근거 선택의 수렴 여부를 다음 네 가지 지표로 측정했습니다.
RCR(Reference Concentration Ratio): 상위 출처로의 집중도
Entropy: 근거 선택의 분산도
Persistence: 동일 anchor의 반복 등장 비율
BAS(Brand Anchor Share): 브랜드 도메인의 점유 비율
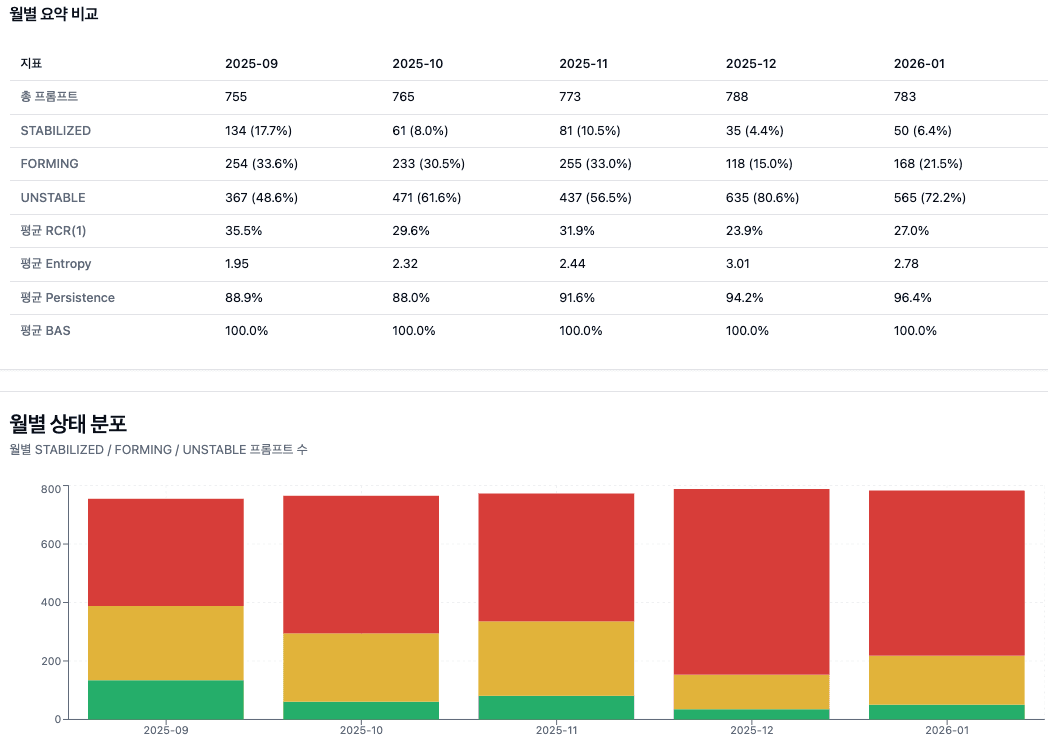
결과는 비교적 명확했습니다. 일부 질문군에서는 anchor 형성이 관측되었지만, 산업 전체 차원에서는 Retrieval Layer가 구조적으로 안정화되었다고 보기 어려웠습니다. STABILIZED 비율은 오히려 감소하는 구간이 있었고, 평균 Entropy는 상승했습니다. 이는 AI가 특정 기준점으로 점점 수렴하고 있다기보다, 여전히 다양한 출처를 분산적으로 선택하고 있음을 의미합니다.
흥미로운 점은 Persistence가 높은 수준을 유지했다는 사실입니다. 이는 AI가 완전히 무작위로 움직이는 것은 아니라는 뜻입니다. 일정한 출처를 반복적으로 참조하는 경향은 존재합니다. 그러나 그 반복이 강력한 anchor 형성으로 이어지지는 않았습니다. 다시 말해, 반복이 곧 수렴은 아니었습니다.
BAS가 100%를 유지한 점 역시 중요한 시사점을 줍니다. 브랜드 도메인이 항상 등장한다는 것은 노출 측면에서는 의미가 있습니다. 그러나 RCR이 낮고 Entropy가 높은 상태라면, 브랜드가 ‘등장’하는 것과 ‘기준점이 되는 것’은 전혀 다른 문제입니다. 노출과 anchor는 같은 차원의 개념이 아닙니다.
결국 이번 실험은 두 가지 질문에 대한 답을 시도한 것이었습니다.
첫째, AI 검색에서 말하는 ‘신뢰’는 반복적 근거 선택의 수렴이라는 구조적 패턴으로 정의할 수 있는가?
둘째, 콘텐츠 발행이 실제로 Retrieval Layer의 안정화로 이어지는가?
전자 업계 220만 건의 데이터가 보여준 것은, 최소한 현재 시점에서 산업 전반의 Retrieval Layer는 아직 구조적으로 고정된 상태가 아니라는 점입니다. 일부 영역에서는 anchor가 형성되지만, 대부분의 질문군에서는 근거 선택이 여전히 분산되어 있습니다.
즉, AI 검색에서의 EEAT는 단순한 콘텐츠 양이나 브랜드 노출로 설명되기 어렵습니다. 신뢰는 ‘많이 등장함’이 아니라, ‘반복적으로 동일하게 선택됨’이라는 형태로 관측되어야 합니다. 그리고 그 수렴이 실제 데이터 상에서 확인될 때에만, 우리는 비로소 Retrieval Layer가 안정화되었다고 말할 수 있습니다.
Chainshift Daniel © 2026 ChainShift. All rights reserved. Unauthorized reproduction and redistribution prohibited.